[1] "spec_tbl_df" "tbl_df" "tbl" "data.frame" Spotify Exploratory Dataset Analysis
Clean data
The new data with no duplicates
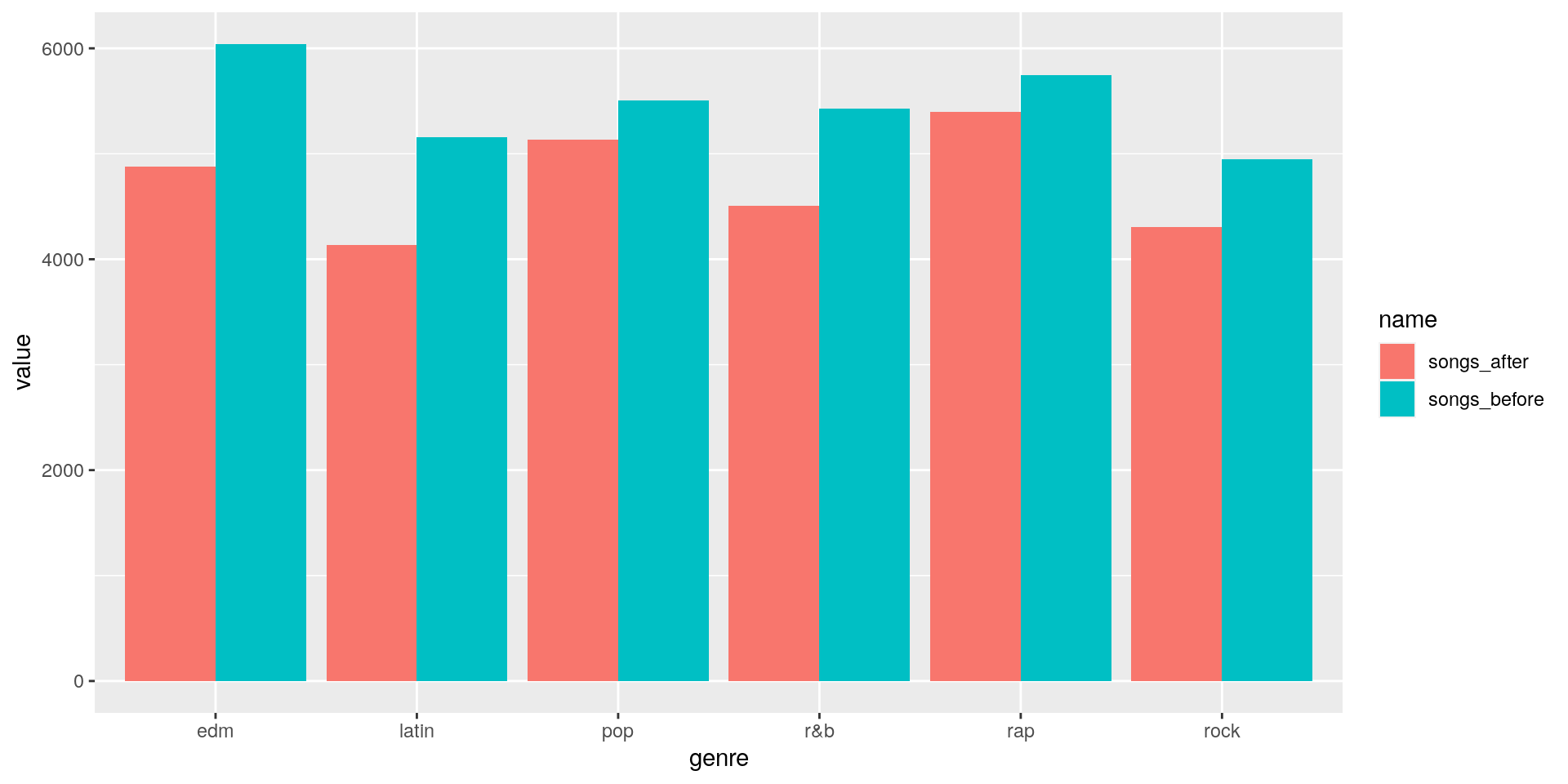
edm latin pop r&b rap rock 4877 4137 5132 4504 5401 4305![]()
Initial Data Exploration
- Most popular artists

Initial Data Exploration
- Most popular albums

Initial Data Exploration
- Most popular genres

Latin
Latin stands out in danceability and valence.
- danceability

Latin
- Valance

Release Date
- Is there a relationship between album release date and popularity?
- Are features affected by album release date?

Release Date
The massive dips in the plot are caused by small number of observations around the year 1960 which is clear in the bar plot below.

Correlation
What’s the correlation between energy, loudness and acousticness?
Positive correlation between energy and loudness
Negative correlation between energy and acousticness

Correlation
- Does this correlation exist in a specific genre?

Correlation
- Does this correlation exist in a specific genre?

Track duration
Does the track duration affect the popularity of the song?
